Build new functionality with Change Data Capture - Instructions
1. Your lab environment
|
Before you proceed it is critical that your lab environment is completely ready before executing the lab instructions. |
-
Access the Workshop Deployer browser tab and check if the Build new functionality with Change Data Capture card has turned green. This indicates that the module has been fully deployed and is ready to use.
Figure 1. Module Readiness on Workshop Deployer
2. Deployment Overview
The architecture of the Cashback service looks as follows:
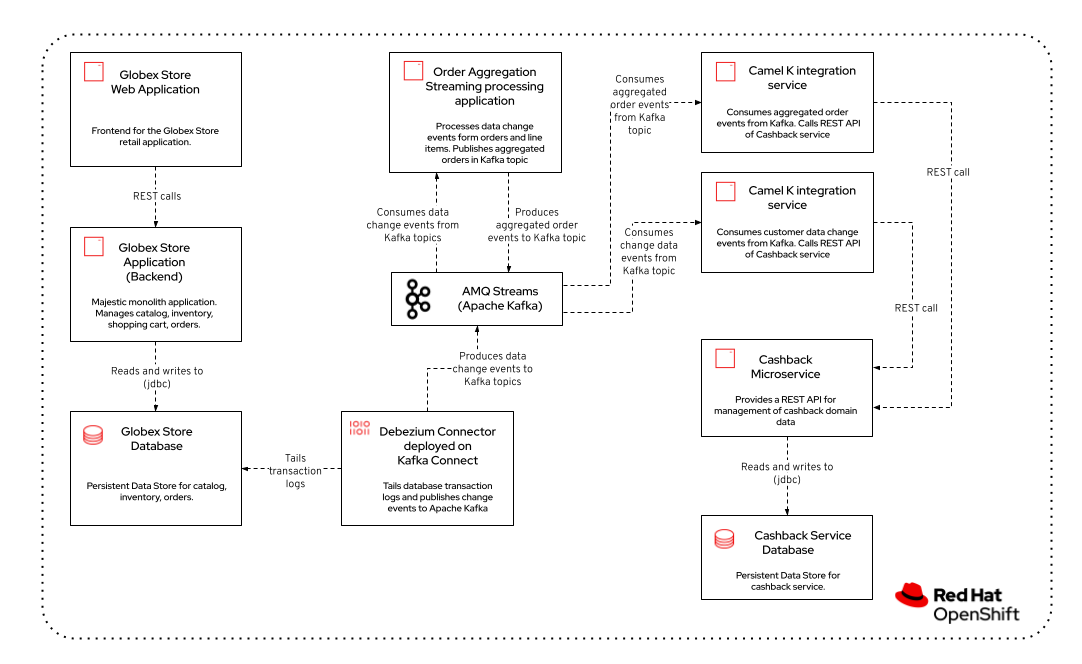
Most of the components have been deployed for you as part of the provisioning of the lab. What is missing is the Debezium connector to power Change Data Capture, and the Camel K integration services to populate the cashback service with customer and order data.