Build new functionality with Change Data Capture - Introduction
In this module you discover how you can leverage Change Data Capture to build out new functionality with minimal impact on existing applications.
Business context
As mentioned in the introduction module of the workshop, Globex went through a first modernization phase for their retail web application, moving from a legacy monolith to a containerized application. Now the business would like to introduce new functionality: they want to introduce a cashback program, rewarding users buying products through the web site. For every purchase, the user would get a small percentage of the total order value as a cashback that they can use on follow-up orders.
Technical considerations
There are a lot of ways to approach this new requirement. The most straightforward would be to build the cashback functionality directly into the Globex retail application. After all, since the modernization of the application, it should be a lot easier to add new functionality compared to the days of the legacy app, when it could easily take several months to bring new functionality into production. However, the technical teams are reluctant to add major new functionality to the Globex application, for fear of ending up again with a complex, hard to maintain and hard to deploy application. They very much prefer a microservices approach, where new functionality is added as a separate set of services which can be developed, deployed and maintained independently.
The cashback service will need access to the information of the orders made through the retail web site, which is stored in the retail app’s database. A possible solution could consist in a microservice that polls the order tables at regular interval, extracts new orders and calculates and stores earned cashback.
There are a number of issues with this approach. First, in a microservices architecture, it is considered poor practice if a service connects directly into a database owned by another service, as this tends to tightly couple the different services together. Also, the technical teams would prefer a more reactive approach, where the cashback service would be triggered every time an order is created or modified, rather than having to poll the database or call an API at regular intervals.
This is where Change Data Capture comes in.
Change Data Capture
Change Data Capture (CDC) is a well-known software pattern that refers to the process of identifying and capturing changes made to data in a database and delivering those changes in real-time to a downstream process or system, which can then react on those changes.
Typical use cases for CDC include data replication (moving data from one data store to another), populating analytical systems and data warehouses, and data propagation to other services without coupling (one service owns the data, other services keep a local, optimized view of the data). This lab is an example of the latter use case.
In the open source world, Debezium is the de-facto standard for CDC. Debezium records row-level changes within each database table by tailing the transaction log of the database. It transforms the captured changes into a change event stream.
Most commonly, Debezium is deployed as a connector on top of Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating source connectors (that send records into Kafka) and sink connectors (that propagate records from Kafka topics to other systems). Debezium is a source connector, it publishes the change event stream to Kafka topics, typically one topic per monitored database table.
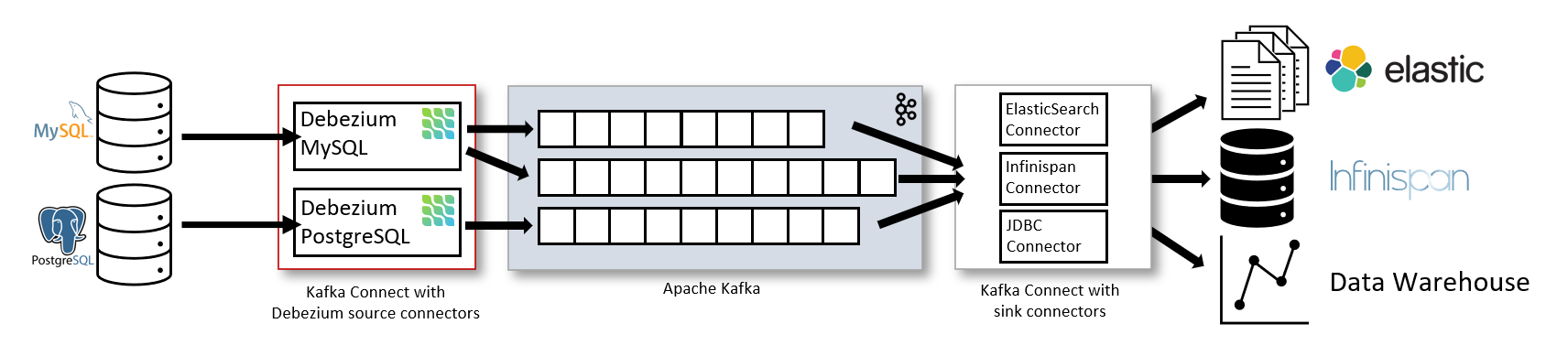
Cashback Service Architecture
With Debezium you can capture changes in the database for those tables you are interested in and stream them to Kafka topics. However, the change event streams in their raw form are most likely not suited to be consumed as such by other applications without transformation or processing of the data.
The Cashback service needs customer and order data to build its local view of customers and orders. So we could have the service directly consume from the Kafka topics that contain the change events and do the required transformations and aggregations inside the Cashback service itself. However, that would tightly couple the service to the CDC solution, which is something we want to avoid.
An alternative is for the Cashback service to have a domain specific API, and have an integration layer that bridges the CDC layer and the Cashback service API.
The Cashback service has a REST API which expects customer and order data. The implementation of the API populates the local database of the service.
For the customer data, an integration service consumes the change events from the customer table, extracts the relevant information from the change event and calls the Cashback service REST API.
For the order data, things are a bit more complex. The cashback service expects the total value for each order, which is not readily available in the change event streams. In the Globex database, the value of each order line item is stored as part of the line item entity, but the total order value is not stored. This means we need to combine the change events from orders and line items in order to obtain the total value for each order. This can be done by leveraging a streaming processing library, which allows to process, transform, join and aggregate streams of events into new event streams.
So the complete architecture consists of:
-
Debezium: tails the transaction logs of the Globex retail database and creates change events which are sent to kafka topics (typically 1 distinct topic per database table).
-
Cashback service: stores a local view of customers and orders in its own database. Exposes a REST API.
-
Customer integration service: consumes the customer change events from Kafka, extracts the relevant information and calls the Cashback service REST API for each customer change event.
-
Order aggregation processing service: consumes the order and line item change events from Kafka. Joins the two event streams by order ID and aggregates them to obtain the total order value. The resulting aggregated order events are published into a Kafka topic.
-
Aggregated order integration service: consumes from the aggregated order events from Kafka, and calls the Cashback service REST API for each aggregated order event.
A graphical representation of the architecture:
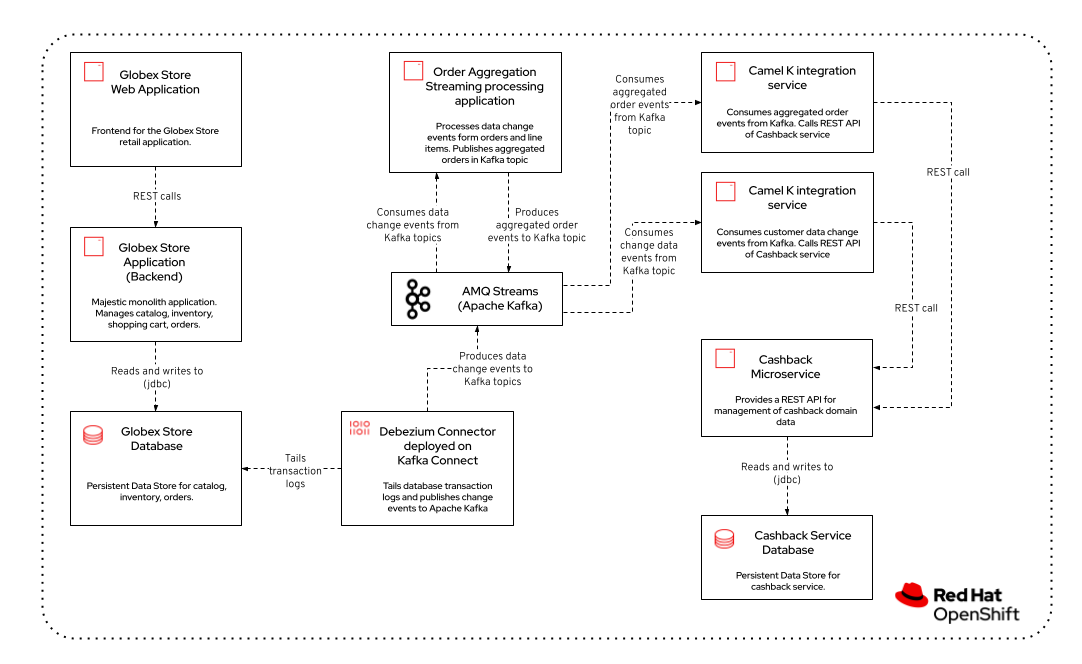
Cashback Service Implementation
In the next chapter, you will be guided through the implementation and deployment of the Cashback service. Of course this entails way more than can be achieved during a workshop, so instead most components are already in place, and you will focus on a couple of key activities to deploy and run the solution.
Proceed to the instructions for this module.